Neurosymbolic Software Tutorial - Regression - Solutions#
Instruction#
Navigating this notebook on Google Colab: There will be text blocks and code blocks throughout the notebook. The text blocks, such as this one, will contain instructions and questions for you to consider. The code blocks, such as the one below, will contain executable code. Sometimes you will have to modify the code blocks following the instructions in the text blocks. You can run the code block by either pressing control/cmd + enter or by clicking the arrow on left-hand side as shown.
@TODOSaving Work: If you wish to save your work in this .ipynb, we recommend downloading the compressed repository from GitHub, unzipping it, uploading it to Google Drive, and opening this notebook from within Google Drive.
Outline#
Part 1: Data Exploration
We’re going to define a function
datagen()and plot trajectories generated with datagen.Exercise: Before reading through the code, look at the trajectory plot and hypothesize what the underlying function might be. Write down what mathematical operators (
sin,pow,exp, etc.) would be useful to discover the underlying function.
Part 2: DSL Generation
We’re going to formalize our intuition by writing a DSL. Write code for the DSL.
Exercise: Modify the DSL with the mathematical operators we wrote down earlier.
Part 3: Program Generation
We’re going to use Neural guided search (NEAR) to search for the best-fit program in the DSL.
Part 4: Program Inspection
We will render the program found by NEAR and inspect it’s performance.
Exercise: Inspect the program found after search. Try different hyperparamters.
Part 1: Data Exploration#
Cell 1: Define
datagen()and save data.Cell 2: Plot the saved data.
Cell 3: Exercise
%load_ext autoreload
%autoreload 2
import os
import numpy as np
IS_REGRESSION = True
def datagen(B, T, *, seed, is_regression=False):
rng = np.random.RandomState(seed)
# generates a numpy trajectory of shape
# X = (B, T, d_inp)
# and a numpy target of shape
# Y = (B, T, 1)
X = rng.rand(B, T, 2)
X[:, 0, :] = 0
for t in range(1, T):
step = rng.randn(B, 2) * 0.2
X[:, t, :] = X[:, t-1, :] + step
X = X.astype(np.float32)
# normalize X b/w -1 and 1
X = (X - np.min(X)) / (np.max(X) - np.min(X))
X = (X - 0.5) * 2
if is_regression:
# # y = distance from origin of X
# Y = np.zeros((B, T, 1))
# Y = np.linalg.norm(X, axis=2, keepdims=True)
# Y = Y.reshape(-1, T, 1)
# Y = Y.astype(np.float32)
Y = abs(X[:, :, 0]).reshape(B, T, 1)
# for all values of X > 0, y *= 10 else y *= -10
Y = np.where(X[:, :, 0:1] > 0, Y * 2, Y * 0.5)
else:
# y = quadrant of X
Y = np.zeros((B, T), dtype=int)
for i in range(B):
for j in range(T):
x, y = X[i, j, :]
if x > 0 and y > 0:
Y[i, j] = 0
elif x < 0 and y > 0:
Y[i, j] = 0
elif x < 0 and y < 0:
Y[i, j] = 1
else: # x > 0 and y < 0
Y[i, j] = 1
Y = Y.reshape(B, T, 1)
return X, Y
X_train, y_train = datagen(1000, 10, is_regression=IS_REGRESSION, seed=1)
X_test, y_test = datagen(50, 10, is_regression=IS_REGRESSION, seed=0)
# save data
os.makedirs('../data/regression_example/', exist_ok=True)
np.save('../data/regression_example/train_ex_data.npy', X_train)
np.save('../data/regression_example/train_ex_labels.npy', y_train)
np.save('../data/regression_example/test_ex_data.npy', X_test)
np.save('../data/regression_example/test_ex_labels.npy', y_test)
import matplotlib.pyplot as plt
import matplotlib
from matplotlib.colors import Normalize
def plot_trajectory(X, Y, is_regression=False):
B, T, _ = X.shape
if is_regression:
cmap_name = 'jet'
colorbar_label = "Distance from origin"
title = "Trajectories and their distances from origin"
norm = Normalize(vmin=Y.min(), vmax=Y.max())
else:
cmap_name = 'jet'
colorbar_label = "Quadrant"
title = "Trajectories and their quadrants"
norm = Normalize(vmin=Y.min(), vmax=Y.max())
for b in range(B):
trajectory = X[b]
output = Y[b].squeeze()
plt.scatter(trajectory[:, 0], trajectory[:, 1], c=output, marker='o', cmap=cmap_name, norm=norm)
plt.plot(trajectory[:, 0], trajectory[:, 1], alpha=0.2, color='gray')
plt.colorbar(label=colorbar_label)
plt.title(title)
plt.xlim(-1, 1)
plt.ylim(-1, 1)
plt.grid(True)
plt.show()
# Hope its clear that we are trying to predict the distance from origin
plot_trajectory(X_test, y_test, is_regression=IS_REGRESSION)
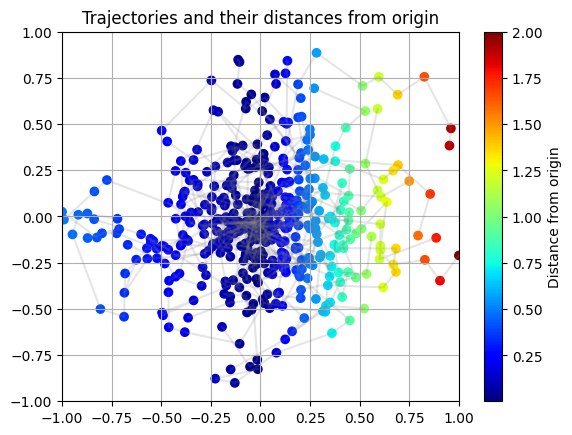
Exercise#
Observe the scatterplot above. Hypothesize what underlying function would allow us to generate this data. Concretely, write down the mathematical operators (sin, pow, exp, etc.) that would be useful to discover the underlying function.
Spoiler! Click to see the answer!
y increases linearly with abs(X). Also, the rate of increase of y is higher for X > 0 than for X <= 0.Some useful operators are:
mul: (np.array, np.array) -> (np.array): Return elementwise multiplication of two arrays of same shape.@TODO
Part 2: DSL Generation#
Cell 1: Predefined DSL.
Exercise: Augment the DSL with the operators you wrote down earlier. This is most likely the hardest part of this tutorial!
import torch
import torch.nn as nn
from neurosym.dsl.dsl_factory import DSLFactory
from neurosym.examples.near.operations.basic import ite_torch
from neurosym.examples.near.operations.lists import fold_torch, map_torch
def simple_dsl(L, O):
dslf = DSLFactory(L=L, O=O, max_overall_depth=5)
dslf.typedef("fL", "{f, $L}")
# dslf.concrete("add", "() -> ($fL, $fL) -> $fL", lambda: lambda x, y: x + y)
# dslf.concrete("mul", "() -> ($fL, $fL) -> $fL", lambda: lambda x, y: x * y)
# dslf.concrete("fold", "((#a, #a) -> #a) -> [#a] -> #a", lambda f: lambda x: fold_torch(f, x))
dslf.concrete("sum", "() -> $fL -> f", lambda: lambda x: torch.sum(x, dim=-1).unsqueeze(-1))
dslf.parameterized("linear_bool", "() -> $fL -> f", lambda lin: lin, dict(lin=lambda: nn.Linear(L, 1)))
dslf.parameterized("linear", "() -> $fL -> $fL", lambda lin: lin, dict(lin=lambda: nn.Linear(L, L)))
dslf.parameterized("output", "(([$fL]) -> [$fL]) -> [$fL] -> [{f, $O}]", lambda f, lin: lambda x: lin(f(x)), dict(lin=lambda: nn.Linear(L, O)))
dslf.concrete("ite", "(#a -> f, #a -> #a, #a -> #a) -> #a -> #a", lambda cond, fx, fy: ite_torch(cond, fx, fy))
dslf.concrete("map", "(#a -> #b) -> [#a] -> [#b]", lambda f: lambda x: map_torch(f, x))
# dslf.concrete("compose", "(#a -> #b, #b -> #c) -> #a -> #c", lambda f, g: lambda x: g(f(x)))
dslf.prune_to("[{f, $L}] -> [{f, $O}]")
return dslf.finalize()
dsl = simple_dsl(X_test.shape[-1], y_test.shape[-1])
print(dsl.render())
/home/asehgal/env/miniconda3/envs/neurosym-lib/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
sum :: () -> {f, 2} -> f
ite :: (#a -> f, #a -> #a, #a -> #a) -> #a -> #a
map :: (#a -> #b) -> [#a] -> [#b]
linear_bool[lin] :: () -> {f, 2} -> f
linear[lin] :: () -> {f, 2} -> {f, 2}
output[lin] :: ([{f, 2}] -> [{f, 2}]) -> [{f, 2}] -> [{f, 1}]
Exercise#
Augment the DSL above with the operators you wrote down earlier.
Part 3: Program Generation#
We’re going to use neural guided search to search for the program in the DSL that maximally fits the dataset.
Cell 1: Define a pytorch dataset from the saved data.
Cell 2: Define
neural_dsl. This DSL extend the DSL we created with neural modules.Cell 3: Define optimization functions to train module parameters.
Cell 4: Define a stopping condition for the search.
Cell 5: Define the search space and initiate the search.
from neurosym.datasets.load_data import DatasetFromNpy, DatasetWrapper
def dataset_factory(train_seed):
return DatasetWrapper(
DatasetFromNpy(
"../data/regression_example/train_ex_data.npy",
"../data/regression_example/train_ex_labels.npy",
train_seed,
),
DatasetFromNpy(
"../data/regression_example/test_ex_data.npy",
"../data/regression_example/test_ex_labels.npy",
None,
),
batch_size=200,
)
datamodule = dataset_factory(42)
input_dim, output_dim = datamodule.train.get_io_dims()
if IS_REGRESSION:
output_dim = 1
print(input_dim, output_dim)
2 1
import neurosym as ns
from neurosym.examples import near
t = ns.TypeDefiner(L=input_dim, O=output_dim)
t.typedef("fL", "{f, $L}")
t.typedef("fO", "{f, $O}")
neural_dsl = near.NeuralDSL.from_dsl(
dsl=dsl,
modules={
**near.create_modules(
"mlp",
[t("($fL) -> $fL"), t("($fL) -> $fO")],
near.mlp_factory(hidden_size=10),
),
**near.create_modules(
"rnn_seq2seq",
[t("([$fL]) -> [$fL]"), t("([$fL]) -> [$fO]")],
near.rnn_factory_seq2seq(hidden_size=10),
),
},
)
from neurosym.utils.imports import import_pytorch_lightning
pl = import_pytorch_lightning()
def regression_mse_loss(
predictions: torch.Tensor, targets: torch.Tensor
) -> torch.Tensor:
"""
Not used. Retained for reference for implementing a regression loss.
"""
predictions = predictions.view(-1, predictions.shape[-1])
targets = targets.view(-1, targets.shape[-1])
return torch.nn.functional.mse_loss(predictions, targets)
def regression_smooth_l1_loss(
predictions: torch.Tensor, targets: torch.Tensor
) -> torch.Tensor:
"""
MSE loss is sensitive to outliers. Smooth L1 loss deals with outliers by
using MSE loss when L1 distance is less than beta and a diminished
L1 loss otherwise.
"""
predictions = predictions.view(-1, predictions.shape[-1])
targets = targets.view(-1, targets.shape[-1])
return torch.nn.functional.smooth_l1_loss(predictions, targets, beta=1.0)
trainer_cfg = near.NEARTrainerConfig(
lr=1e-3,
max_seq_len=100,
n_epochs=30,
num_labels=output_dim,
train_steps=len(datamodule.train),
loss_callback=regression_smooth_l1_loss,
scheduler='none',
optimizer=torch.optim.Adam,
)
validation_cost = near.ValidationCost(
trainer_cfg=trainer_cfg,
neural_dsl=neural_dsl,
datamodule=datamodule,
enable_model_summary=False,
enable_progress_bar=True,
callbacks=[
pl.callbacks.EarlyStopping(monitor="val_loss", min_delta=1e-4, patience=5)
],
check_val_every_n_epoch=1,
)
g = near.near_graph(
neural_dsl,
ns.parse_type(
s="([{f, $L}]) -> [{f, $O}]", env=ns.TypeDefiner(L=input_dim, O=output_dim)
),
is_goal=neural_dsl.program_has_no_holes,
)
iterator = ns.search.bounded_astar(g, validation_cost, max_depth=7)
best_program_nodes = []
# Let's collect the top four programs
while len(best_program_nodes) <= 3:
try:
node = next(iterator)
cost = validation_cost(node)
best_program_nodes.append((node, cost))
except StopIteration:
print("No more programs found.")
break
Epoch 5: 100%|██████████| 5/5 [00:00<00:00, 76.15it/s, train_loss=0.0169, val_loss=0.0715]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 81.55it/s, train_loss=0.0129, val_loss=0.0477]
Epoch 21: 100%|██████████| 5/5 [00:00<00:00, 86.01it/s, train_loss=0.012, val_loss=0.0565]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 78.88it/s, train_loss=0.0106, val_loss=0.0487]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 91.98it/s, train_loss=0.062, val_loss=0.138]
Epoch 5: 100%|██████████| 5/5 [00:00<00:00, 88.11it/s, train_loss=0.0196, val_loss=0.0739]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 82.76it/s, train_loss=0.0101, val_loss=0.0459]
Epoch 5: 100%|██████████| 5/5 [00:00<00:00, 98.76it/s, train_loss=0.0136, val_loss=0.0484]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 111.60it/s, train_loss=0.0129, val_loss=0.0419]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 107.62it/s, train_loss=0.018, val_loss=0.0694]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 103.09it/s, train_loss=0.0192, val_loss=0.061]
Epoch 25: 100%|██████████| 5/5 [00:00<00:00, 94.62it/s, train_loss=0.0159, val_loss=0.065]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 115.60it/s, train_loss=0.102, val_loss=0.198]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 93.43it/s, train_loss=0.0514, val_loss=0.136]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 88.46it/s, train_loss=0.075, val_loss=0.153]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 108.68it/s, train_loss=0.0296, val_loss=0.0516]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 90.51it/s, train_loss=0.0749, val_loss=0.161]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 86.76it/s, train_loss=0.011, val_loss=0.0434]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 107.46it/s, train_loss=0.0183, val_loss=0.0712]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 90.54it/s, train_loss=0.0168, val_loss=0.0663]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 108.91it/s, train_loss=0.0159, val_loss=0.0638]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 108.51it/s, train_loss=0.0227, val_loss=0.0639]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 99.50it/s, train_loss=0.0734, val_loss=0.0812]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 113.43it/s, train_loss=0.0509, val_loss=0.0766]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 90.50it/s, train_loss=0.0183, val_loss=0.0723]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 94.60it/s, train_loss=0.0169, val_loss=0.0666]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 86.44it/s, train_loss=0.0104, val_loss=0.0412]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 96.48it/s, train_loss=0.0101, val_loss=0.0414]
Epoch 9: 100%|██████████| 5/5 [00:00<00:00, 99.67it/s, train_loss=0.0158, val_loss=0.0623]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 87.19it/s, train_loss=0.0121, val_loss=0.031]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 81.32it/s, train_loss=0.0116, val_loss=0.0469]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 95.17it/s, train_loss=0.019, val_loss=0.0732]
Epoch 5: 100%|██████████| 5/5 [00:00<00:00, 94.86it/s, train_loss=0.0164, val_loss=0.0672]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 92.12it/s, train_loss=0.0109, val_loss=0.0423]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 97.03it/s, train_loss=0.0345, val_loss=0.0975]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 90.46it/s, train_loss=0.00881, val_loss=0.0364]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 91.72it/s, train_loss=0.0237, val_loss=0.0644]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 98.62it/s, train_loss=0.0167, val_loss=0.0693]
Epoch 21: 100%|██████████| 5/5 [00:00<00:00, 107.48it/s, train_loss=0.021, val_loss=0.0766]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 87.18it/s, train_loss=0.0252, val_loss=0.0849]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 78.97it/s, train_loss=0.0135, val_loss=0.0418]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 99.05it/s, train_loss=0.0174, val_loss=0.065]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 96.07it/s, train_loss=0.034, val_loss=0.109]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 91.29it/s, train_loss=0.0131, val_loss=0.0513]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 87.90it/s, train_loss=0.0162, val_loss=0.0646]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 92.69it/s, train_loss=0.0111, val_loss=0.0458]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 94.59it/s, train_loss=0.0181, val_loss=0.0719]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 93.24it/s, train_loss=0.0118, val_loss=0.0441]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 95.15it/s, train_loss=0.00941, val_loss=0.0342]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 93.21it/s, train_loss=0.0204, val_loss=0.0652]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 82.32it/s, train_loss=0.151, val_loss=0.238]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 93.00it/s, train_loss=0.0133, val_loss=0.0565]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 88.80it/s, train_loss=0.104, val_loss=0.180]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 86.94it/s, train_loss=0.0104, val_loss=0.0419]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 100.10it/s, train_loss=0.0186, val_loss=0.0726]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 97.77it/s, train_loss=0.00933, val_loss=0.035]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 90.01it/s, train_loss=0.0127, val_loss=0.044]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 86.31it/s, train_loss=0.0495, val_loss=0.124]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 99.84it/s, train_loss=0.00868, val_loss=0.031]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 96.67it/s, train_loss=0.0154, val_loss=0.0645]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 110.13it/s, train_loss=0.130, val_loss=0.229]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 93.60it/s, train_loss=0.0128, val_loss=0.0483]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 110.71it/s, train_loss=0.0179, val_loss=0.0713]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 107.19it/s, train_loss=0.0163, val_loss=0.0664]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 106.31it/s, train_loss=0.0135, val_loss=0.0546]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 106.51it/s, train_loss=0.0165, val_loss=0.0659]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 102.39it/s, train_loss=0.062, val_loss=0.126]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 87.68it/s, train_loss=0.0186, val_loss=0.0724]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 87.27it/s, train_loss=0.00973, val_loss=0.039]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 86.04it/s, train_loss=0.0138, val_loss=0.056]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 87.40it/s, train_loss=0.0101, val_loss=0.0306]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 96.83it/s, train_loss=0.0157, val_loss=0.069]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 97.59it/s, train_loss=0.0528, val_loss=0.125]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 94.54it/s, train_loss=0.189, val_loss=0.269]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 95.19it/s, train_loss=0.0197, val_loss=0.0735]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 91.66it/s, train_loss=0.355, val_loss=0.478]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 91.84it/s, train_loss=0.032, val_loss=0.0633]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 74.53it/s, train_loss=0.0212, val_loss=0.0557]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 88.65it/s, train_loss=0.00913, val_loss=0.0326]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 89.29it/s, train_loss=0.0104, val_loss=0.0349]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 87.87it/s, train_loss=0.00865, val_loss=0.037]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 59.99it/s, train_loss=0.0167, val_loss=0.0554]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 93.41it/s, train_loss=0.0261, val_loss=0.0665]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 94.84it/s, train_loss=0.0109, val_loss=0.0485]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 85.68it/s, train_loss=0.0261, val_loss=0.0897]
Epoch 29: 100%|██████████| 5/5 [00:00<00:00, 84.49it/s, train_loss=0.0103, val_loss=0.0343]
No more programs found.
Part 4: Program Inspection#
A key benefit of program synthesis is that the output program is interpretable.
Cell 1: Render the best program.
Cell 2: Visualize the output space of the best program.
Exercise: Does the program discovered line up with your initial hypotheses?
def plot_expression(sexpr, x=0.5, y=1, level=1, dx=0.1, ax=None, text_offset=0.02):
if ax is None:
fig, ax = plt.subplots(figsize=(5, 5))
ax.set_axis_off()
ax.text(x, y, sexpr.symbol, ha='center', va='center',
bbox=dict(facecolor='white', edgecolor='black', boxstyle='round,pad=0.5'))
num_children = len(sexpr.children)
if num_children > 0:
child_y = y - 1 / level
for i, child in enumerate(sexpr.children):
child_x = x - (dx * (num_children - 1) / 2) + i * dx
ax.plot([x, child_x], [y - text_offset, child_y + text_offset], 'k-')
plot_expression(child, x=child_x, y=child_y, level=level + 1, dx=dx / 2, ax=ax, text_offset=text_offset)
if ax is None:
plt.show()
best_program_nodes = sorted(best_program_nodes, key=lambda x: x[1])
for i, (node, cost) in enumerate(best_program_nodes):
print("({i}) Cost: {cost:.4f}, {program}".format(i=i, program=ns.render_s_expression(node.program), cost=cost))
best_program_node = best_program_nodes[0]
print(ns.render_s_expression(best_program_node[0].program))
plot_expression(best_program_node[0].program)
(0) Cost: 0.0666, (output (map (ite (sum) (linear) (linear))))
(1) Cost: 0.0694, (output (map (linear)))
(2) Cost: 0.0812, (output (map (ite (linear_bool) (linear) (linear))))
(output (map (ite (sum) (linear) (linear))))
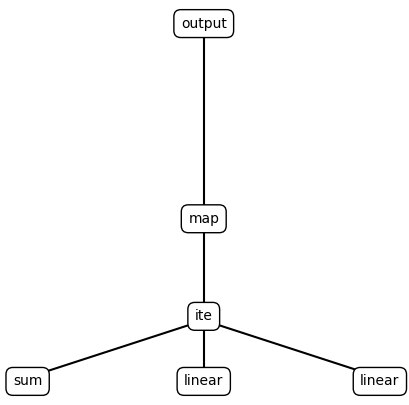
best_program_node = best_program_nodes[0]
module = near.TorchProgramModule(dsl=neural_dsl, program=best_program_node[0].program)
# # a satisfactory set of weights. @TODO: Remove
# # lin.weight.data = torch.tensor([[0., 1.], [0., 0.]])
# lin.bias.data = torch.tensor([0., 0.])
pl_model = near.NEARTrainer(module, config=trainer_cfg)
trainer = pl.Trainer(
max_epochs=2000,
devices="auto",
accelerator="cpu",
enable_checkpointing=False,
enable_model_summary=False,
enable_progress_bar=False,
logger=False,
deterministic=True,
)
trainer.fit(
pl_model, datamodule.train_dataloader(), datamodule.val_dataloader()
)
grid = np.linspace(-3, 3, 100)
xx, yy = np.meshgrid(grid, grid)
X = np.stack([xx, yy], axis=-1)
X = X.reshape(-1, 2)
X = torch.tensor(X, dtype=torch.float32)
Y = module(X.unsqueeze(0)).squeeze(0)
Y = Y.detach().numpy()
Y = Y.reshape(100, 100, 1)
y = Y
# Using imshow to plot y as a heatmap
plt.figure(figsize=(8, 6))
plt.imshow(y, origin='lower', extent=(-3, 3, -3, 3), cmap='viridis')
plt.colorbar(label="Distance from origin")
plt.title("Output heatmap\n{program}".format(program=ns.render_s_expression(best_program_node[0].program)))
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
plt.show()
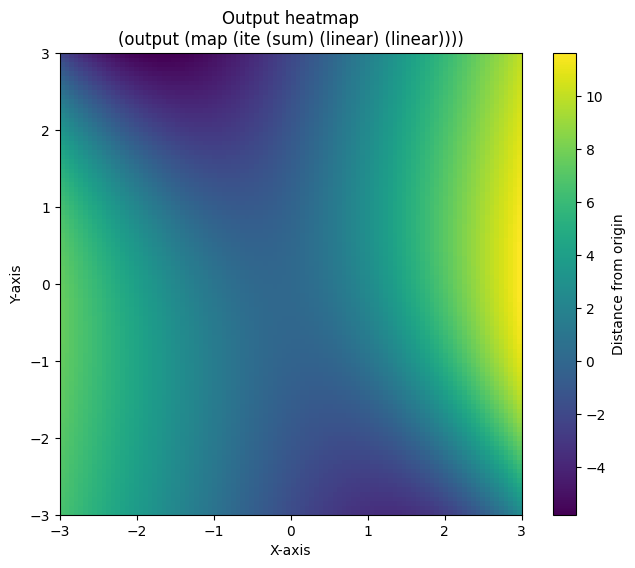
Notice that the output heatmap plots program output within the range [-3, 3] while the data we trained on was within the range [-1, 1].
Exercise#
Does the output heatmap line up with the trajectory data we visualized in part 1? Does the program and the heatmap line up with our initial hypotheses?