Notebook 3
Contents
Notebook 3#
![]()
Instructions#
README
Navigating this notebook on Google Colab: There will be text blocks and code blocks throughout the notebook. The text blocks, such as this one, will contain instructions and questions for you to consider. The code blocks, such as the one below, will contain executible code. Sometimes you will have to modify the code blocks following the instructions in the text blocks. You can run the code block by either pressing
control/cmd + enteror by clicking the arrow on left-hand side as shown.
Saving Work: If you wish to save your work in this
.ipynb, we recommend downloading the compressed repository from GitHub, unzipping it, uploading it to Google Drive, opening this notebook from within Google Drive, and settingWITHIN_GDRIVEtoTrue.This notebook doesn’t require any modifications inside the
code_and_datadirectory for a base walkthrough, but if you want to work on the optional exercises throughout the notebook, you will need to modifydsl.ipynbwhich will require saving your work. However, as a workaround, you can directly make changes todsl.pyandnear.pyand restart the runtime usingRuntime > Restart Runtime. The video below shows how to do this.
Finally, this notebook requires a NVIDIA GPU for training. Google Colab allows access to one GPU instance for free (at a given time). Go to
Runtime > Manage Sessions > Accelerator: GPU.
# (Optional) Are you loading data from within Google Drive?
WITHIN_GDRIVE = False # otherwise: True
# Setup repository and download toy CalMS21 data
if not WITHIN_GDRIVE:
!git clone https://github.com/neurosymbolic-learning/Neurosymbolic_Tutorial.git /content/Neurosymbolic_Tutorial
%cd /content/Neurosymbolic_Tutorial/code_and_data
!gdown 1XPUF4n5iWhQw8v1ujAqDpFefJUVEoT4L && (unzip -o calms21_task1.zip; rm -rf calms21_task1.zip )
else:
from google.colab import drive
drive.mount('/content/drive')
# Change this path to match the corect destination
%cd /content/drive/MyDrive/Neurosymbolic_Tutorial/code_and_data/
import os; assert os.path.exists("dsl.py"), f"Couldn't find `dsl.py` at this location {os.getcwd()}. HINT: Are you within `code_and_data`"
!gdown 1XPUF4n5iWhQw8v1ujAqDpFefJUVEoT4L && (unzip -o calms21_task1.zip; rm -rf calms21_task1.zip )
import os
import matplotlib.pyplot as plt
import numpy as np
fatal: destination path '/content/Neurosymbolic_Tutorial' already exists and is not an empty directory.
/content/Neurosymbolic_Tutorial/code_and_data
Downloading...
From: https://drive.google.com/uc?id=1XPUF4n5iWhQw8v1ujAqDpFefJUVEoT4L
To: /content/Neurosymbolic_Tutorial/code_and_data/calms21_task1.zip
100% 18.2M/18.2M [00:00<00:00, 167MB/s]
Archive: calms21_task1.zip
inflating: data/calms21_task1/test_data.npy
inflating: data/calms21_task1/test_investigation_labels.npy
inflating: data/calms21_task1/test_mount_labels.npy
inflating: data/calms21_task1/test_trajectory_data.npy
inflating: data/calms21_task1/train_data.npy
inflating: data/calms21_task1/train_investigation_labels.npy
inflating: data/calms21_task1/train_mount_labels.npy
inflating: data/calms21_task1/train_trajectory_data.npy
inflating: data/calms21_task1/val_data.npy
inflating: data/calms21_task1/val_investigation_labels.npy
inflating: data/calms21_task1/val_mount_labels.npy
inflating: data/calms21_task1/val_trajectory_data.npy
(Important!) Convert Notebooks to Python Files#
If you update the DSL in dsl.ipynb or the search algorithm in near.ipynb, you need to run this cell again to update the code in this notebook.
!jupyter nbconvert --to python dsl.ipynb
!jupyter nbconvert --to python near.ipynb
[NbConvertApp] Converting notebook dsl.ipynb to python
[NbConvertApp] Writing 41558 bytes to dsl.py
[NbConvertApp] Converting notebook near.ipynb to python
[NbConvertApp] Writing 39669 bytes to near.py
Neural Relaxation Exercise#
Admissible heuristics are heuristics that never overestimate the cost of reaching a goal. These heuristics can be used as part of an informed search algorithm, such as A* search. Here, we use the assumption that sufficiently large neural networks have greater representational power compared to neurosymbolic models or symbolic models, and use this neural relaxation as an admissible heuristic over the program graph search space.

Run the utility code below to set up the training.
!pip install pytorch-lightning # Pytorch lightning is a wrapper around PyTorch.
import os
import torch, numpy as np
import torch.nn as nn
import torch.nn.functional as F
import pytorch_lightning as pl
from sklearn.metrics import f1_score, precision_score, recall_score
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting pytorch-lightning
Downloading pytorch_lightning-1.6.5-py3-none-any.whl (585 kB)
|████████████████████████████████| 585 kB 14.7 MB/s
?25hRequirement already satisfied: numpy>=1.17.2 in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (1.21.6)
Collecting PyYAML>=5.4
Downloading PyYAML-6.0-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl (596 kB)
|████████████████████████████████| 596 kB 58.8 MB/s
?25hRequirement already satisfied: protobuf<=3.20.1 in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (3.17.3)
Requirement already satisfied: typing-extensions>=4.0.0 in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (4.1.1)
Requirement already satisfied: tensorboard>=2.2.0 in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (2.8.0)
Requirement already satisfied: tqdm>=4.57.0 in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (4.64.0)
Collecting pyDeprecate>=0.3.1
Downloading pyDeprecate-0.3.2-py3-none-any.whl (10 kB)
Collecting fsspec[http]!=2021.06.0,>=2021.05.0
Downloading fsspec-2022.5.0-py3-none-any.whl (140 kB)
|████████████████████████████████| 140 kB 56.9 MB/s
?25hCollecting torchmetrics>=0.4.1
Downloading torchmetrics-0.9.2-py3-none-any.whl (419 kB)
|████████████████████████████████| 419 kB 52.3 MB/s
?25hRequirement already satisfied: torch>=1.8.* in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (1.12.0+cu113)
Requirement already satisfied: packaging>=17.0 in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (21.3)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (2.23.0)
Collecting aiohttp
Downloading aiohttp-3.8.1-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl (1.1 MB)
|████████████████████████████████| 1.1 MB 55.2 MB/s
?25hRequirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from packaging>=17.0->pytorch-lightning) (3.0.9)
Requirement already satisfied: six>=1.9 in /usr/local/lib/python3.7/dist-packages (from protobuf<=3.20.1->pytorch-lightning) (1.15.0)
Requirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=2.2.0->pytorch-lightning) (1.8.1)
Requirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=2.2.0->pytorch-lightning) (0.37.1)
Requirement already satisfied: tensorboard-data-server<0.7.0,>=0.6.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=2.2.0->pytorch-lightning) (0.6.1)
Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=2.2.0->pytorch-lightning) (3.3.7)
Requirement already satisfied: grpcio>=1.24.3 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=2.2.0->pytorch-lightning) (1.47.0)
Requirement already satisfied: google-auth<3,>=1.6.3 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=2.2.0->pytorch-lightning) (1.35.0)
Requirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=2.2.0->pytorch-lightning) (0.4.6)
Requirement already satisfied: absl-py>=0.4 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=2.2.0->pytorch-lightning) (1.1.0)
Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=2.2.0->pytorch-lightning) (57.4.0)
Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=2.2.0->pytorch-lightning) (1.0.1)
Requirement already satisfied: cachetools<5.0,>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from google-auth<3,>=1.6.3->tensorboard>=2.2.0->pytorch-lightning) (4.2.4)
Requirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.7/dist-packages (from google-auth<3,>=1.6.3->tensorboard>=2.2.0->pytorch-lightning) (0.2.8)
Requirement already satisfied: rsa<5,>=3.1.4 in /usr/local/lib/python3.7/dist-packages (from google-auth<3,>=1.6.3->tensorboard>=2.2.0->pytorch-lightning) (4.8)
Requirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.7/dist-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard>=2.2.0->pytorch-lightning) (1.3.1)
Requirement already satisfied: importlib-metadata>=4.4 in /usr/local/lib/python3.7/dist-packages (from markdown>=2.6.8->tensorboard>=2.2.0->pytorch-lightning) (4.12.0)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata>=4.4->markdown>=2.6.8->tensorboard>=2.2.0->pytorch-lightning) (3.8.0)
Requirement already satisfied: pyasn1<0.5.0,>=0.4.6 in /usr/local/lib/python3.7/dist-packages (from pyasn1-modules>=0.2.1->google-auth<3,>=1.6.3->tensorboard>=2.2.0->pytorch-lightning) (0.4.8)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (1.24.3)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (2022.6.15)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (2.10)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (3.0.4)
Requirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.7/dist-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard>=2.2.0->pytorch-lightning) (3.2.0)
Collecting frozenlist>=1.1.1
Downloading frozenlist-1.3.0-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl (144 kB)
|████████████████████████████████| 144 kB 48.0 MB/s
?25hCollecting multidict<7.0,>=4.5
Downloading multidict-6.0.2-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (94 kB)
|████████████████████████████████| 94 kB 4.3 MB/s
?25hCollecting yarl<2.0,>=1.0
Downloading yarl-1.7.2-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl (271 kB)
|████████████████████████████████| 271 kB 76.7 MB/s
?25hCollecting asynctest==0.13.0
Downloading asynctest-0.13.0-py3-none-any.whl (26 kB)
Collecting aiosignal>=1.1.2
Downloading aiosignal-1.2.0-py3-none-any.whl (8.2 kB)
Requirement already satisfied: attrs>=17.3.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (21.4.0)
Requirement already satisfied: charset-normalizer<3.0,>=2.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (2.1.0)
Collecting async-timeout<5.0,>=4.0.0a3
Downloading async_timeout-4.0.2-py3-none-any.whl (5.8 kB)
Installing collected packages: multidict, frozenlist, yarl, asynctest, async-timeout, aiosignal, fsspec, aiohttp, torchmetrics, PyYAML, pyDeprecate, pytorch-lightning
Attempting uninstall: PyYAML
Found existing installation: PyYAML 3.13
Uninstalling PyYAML-3.13:
Successfully uninstalled PyYAML-3.13
Successfully installed PyYAML-6.0 aiohttp-3.8.1 aiosignal-1.2.0 async-timeout-4.0.2 asynctest-0.13.0 frozenlist-1.3.0 fsspec-2022.5.0 multidict-6.0.2 pyDeprecate-0.3.2 pytorch-lightning-1.6.5 torchmetrics-0.9.2 yarl-1.7.2
# Utility Functions from Notebook 1
class TrainConfig:
epochs: int = 20
batch_size: int = 32
lr: float = 3e-3
weight_decay: float = 0.0
train_size: int = 2000 # out of 5000
val_size: int = 1000 # out of 5000
test_size: int = 3000 # out of 3000
num_classes: int = 2
config = TrainConfig()
# Dataloader for the CalMS21 dataset
class Calms21Task1Dataset(torch.utils.data.Dataset):
def __init__(self, data_path, investigations_path, transform=None, target_transform=None):
self.data = np.load(data_path)
self.investigations = np.load(investigations_path)
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
x = self.data[idx]
y = self.investigations[idx]
if self.transform:
x = self.transform(x)
if self.target_transform:
y = self.target_transform(y)
return x, y
class Calms21Task1DataModule(pl.LightningDataModule):
def __init__(self, data_dir, batch_size, transform=None, target_transform=None ):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.train_data_path = os.path.join(data_dir, "train_data.npy")
self.train_investigations_path = os.path.join(data_dir, "train_investigation_labels.npy")
self.test_data_path = os.path.join(data_dir, "test_data.npy")
self.test_investigations_path = os.path.join(data_dir, "test_investigation_labels.npy")
self.val_data_path = os.path.join(data_dir, "val_data.npy")
self.val_investigations_path = os.path.join(data_dir, "val_investigation_labels.npy")
self.transform = transform
self.target_transform = target_transform
def setup(self, stage=None):
self.train_dataset = Calms21Task1Dataset(self.train_data_path, self.train_investigations_path, self.transform, self.target_transform)
self.val_dataset = Calms21Task1Dataset(self.val_data_path, self.val_investigations_path, self.transform, self.target_transform)
self.test_dataset = Calms21Task1Dataset(self.test_data_path, self.test_investigations_path, self.transform, self.target_transform)
def train_dataloader(self):
return torch.utils.data.DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return torch.utils.data.DataLoader(self.val_dataset, batch_size=self.batch_size, shuffle=False)
def test_dataloader(self):
return torch.utils.data.DataLoader(self.test_dataset, batch_size=self.batch_size, shuffle=False)
dm = Calms21Task1DataModule(data_dir="data/calms21_task1/", batch_size=32, transform=None, target_transform=None)
dm.setup(None)
def train(model, datamodule, config):
trainer = pl.Trainer(gpus=0, max_epochs=config.epochs)
trainer.fit(model, datamodule)
return model
# Evaluate using F1 score.
test_labels = np.load("data/calms21_task1/test_investigation_labels.npy")
def evaluate(model, data_loader, gt_labels):
predictions = []
for x,_ in data_loader:
predictions.append(torch.argmax(model(x), dim = -1))
predictions = torch.cat(predictions, dim = 0)
f1 = f1_score(test_labels, predictions, average="binary")
precision = precision_score(test_labels, predictions, average="binary")
recall = recall_score(test_labels, predictions, average="binary")
print("F1 score on test set: " + str(f1))
print("Precision on test set: " + str(precision))
print("Recall on test set: " + str(recall))
return predictions, f1, precision, recall
Exercise: The cost of a program is represented by structural cost + the model performance (error in F1 score). Compare performance between:
Program 1:
Window13Avg( Or(MinResNoseKeypointDistSelect,AccelerationSelect) )Program 2:
Window13Avg( Or(AtomToAtomModule,AtomToAtomModule) )
Which program have lower cost in terms of error in F1 score? AtomToAtomModule from program 2 are neural networks, while MinResNoseKeypointDistSelect and AccelerationSelect from program 1 are feature selects with only a small set of weights and bias that are learned. Are you able to find features in DSL_DICT in dsl.ipynb that enables program 1 to perform better than program 2?
Example of a symbolic program#
# Complete program
from dsl_compiler import ExpertProgram
program = "Window13Avg( Or(MinResNoseKeypointDistSelect,AccelerationSelect) )"
config.lr = 1e-2
sample_model = ExpertProgram(program, config=config)
# Use gradient descent to find parameters of multi-variable linear regression.
sample_model = train(sample_model, dm, config=config)
predictions_symbolic, _, _, _ = evaluate(sample_model, dm.test_dataloader(), test_labels)
GPU available: True, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/usr/local/lib/python3.7/dist-packages/pytorch_lightning/trainer/trainer.py:1817: PossibleUserWarning: GPU available but not used. Set `accelerator` and `devices` using `Trainer(accelerator='gpu', devices=1)`.
category=PossibleUserWarning,
Missing logger folder: /content/drive/MyDrive/Neurosymbolic_Summer_School_Tutorials/code_and_data/lightning_logs
| Name | Type | Params
------------------------------
------------------------------
0 Trainable params
0 Non-trainable params
0 Total params
0.000 Total estimated model params size (MB)
F1 score on test set: 0.5983960518198643
Precision on test set: 0.5382907880133185
Recall on test set: 0.6736111111111112
Example of a Neurosymbolic Program#
How does the performance compare to the symbolic program above?
# Neurosymbolic
program = "Window13Avg( Or(AtomToAtomModule,AtomToAtomModule) )"
config.lr = 1e-2
sample_model = ExpertProgram(program, config=config)
# Use gradient descent to find parameters of multi-variable linear regression.
sample_model = train(sample_model, dm, config=config)
predictions_symbolic, _, _, _ = evaluate(sample_model, dm.test_dataloader(), test_labels)
GPU available: True, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/usr/local/lib/python3.7/dist-packages/pytorch_lightning/trainer/trainer.py:1817: PossibleUserWarning: GPU available but not used. Set `accelerator` and `devices` using `Trainer(accelerator='gpu', devices=1)`.
category=PossibleUserWarning,
| Name | Type | Params
------------------------------
------------------------------
0 Trainable params
0 Non-trainable params
0 Total params
0.000 Total estimated model params size (MB)
F1 score on test set: 0.7103977669225401
Precision on test set: 0.7138849929873773
Recall on test set: 0.7069444444444445
Example of a Neural Module#
How does the performance compare to the neurosymbolic program?
# This is an RNN = basically fully neural. How does the error compare?
program = "ListToAtomModule"
config.lr = 1e-2
sample_model = ExpertProgram(program, config=config)
# Use gradient descent to find parameters of multi-variable linear regression.
sample_model = train(sample_model, dm, config=config)
predictions_symbolic, _, _, _ = evaluate(sample_model, dm.test_dataloader(), test_labels)
GPU available: True, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/usr/local/lib/python3.7/dist-packages/pytorch_lightning/trainer/trainer.py:1817: PossibleUserWarning: GPU available but not used. Set `accelerator` and `devices` using `Trainer(accelerator='gpu', devices=1)`.
category=PossibleUserWarning,
| Name | Type | Params
------------------------------
------------------------------
0 Trainable params
0 Non-trainable params
0 Total params
0.000 Total estimated model params size (MB)
F1 score on test set: 0.7579843860894251
Precision on test set: 0.7750362844702468
Recall on test set: 0.7416666666666667
NEAR: Astar Search#
We can use NEAR as a heuristic to guide A* search. We maintain a frontier of nodes (starting with an empty program), and at each iteration we choose a node on the frontier to explore by using the NEAR heuristic with a structural cost to estimate its path cost. The search terminates when the frontier is empty, after which we return the best complete program found during our search.
NEAR with Base DSL#
How does the programs found by NEAR differ from enumeration through the search process? How does the frontier size change during the search process?
!yes| python train.py \
--algorithm astar-near \
--exp_name investigation_base \
--trial 1 \
--seed 1 \
--dsl_str "default" \
--train_data "data/calms21_task1/train_data.npy" \
--test_data "data/calms21_task1/test_data.npy" \
--valid_data "data/calms21_task1/val_data.npy" \
--train_labels "data/calms21_task1/train_investigation_labels.npy" \
--test_labels "data/calms21_task1/test_investigation_labels.npy" \
--valid_labels "data/calms21_task1/val_investigation_labels.npy" \
--input_type "list" \
--output_type "atom" \
--input_size 18 \
--output_size 1 \
--num_labels 1 \
--lossfxn "bcelogits" \
--frontier_capacity 8 \
--max_num_children 10 \
--max_depth 5 \
--max_num_units 32 \
--min_num_units 16 \
--learning_rate 0.0001 \
--neural_epochs 4 \
--symbolic_epochs 12 \
--class_weights "2.0"
Seed is 1
Experiment log and results saved at: results/investigation_base_astar-near_sd_1_001
Training root program ...
/content/drive/MyDrive/neurosymbolic_summer_school_notebooks/code_and_data_4/near.py:222: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:210.)
batch_input = [torch.tensor(traj) for traj in batch]
Initial training complete. F1-Score from program is 0.5791
CURRENT program has depth 0, fscore inf: Start(ListToAtomModule)
Training child program: Start(Or(ListToAtomModule, ListToAtomModule))
DEBUG: f-score 0.3788709677419355
Training child program: Start(And(ListToAtomModule, ListToAtomModule))
DEBUG: f-score 0.562713567839196
Training child program: Start(Window5Avg(AtomToAtomModule))
DEBUG: f-score 0.9176923076923077
Frontier length is: 3
Total time elapsed is 9.576
CURRENT program has depth 1, fscore 0.3789: Start(Or(ListToAtomModule, ListToAtomModule))
Training child program: Start(Or(Window5Avg(AtomToAtomModule), ListToAtomModule))
DEBUG: f-score 0.48861297539149895
Frontier length is: 3
Total time elapsed is 13.502
CURRENT program has depth 2, fscore 0.4886: Start(Or(Window5Avg(AtomToAtomModule), ListToAtomModule))
Training child program: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(AtomToAtomModule)))
DEBUG: f-score 0.4488495575221238
Frontier length is: 3
Total time elapsed is 17.936
CURRENT program has depth 3, fscore 0.4488: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(AtomToAtomModule)))
Training child program: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(ResAngleHeadBodySelect())))
DEBUG: f-score 0.5697273133661154
Training child program: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(SpeedSelect())))
DEBUG: f-score 0.5679435702658711
Training child program: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(TangentialVelocitySelect())))
DEBUG: f-score 0.643960396039604
Training child program: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(AccelerationSelect())))
DEBUG: f-score 0.6175444264943457
Training child program: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(RelativeSocialAngleSelect())))
DEBUG: f-score 0.6677116864940518
Training child program: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(AxisRatioSelect())))
DEBUG: f-score 0.9162035763411279
Training child program: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(OverlapBboxesSelect())))
DEBUG: f-score 0.4535188866799205
POP Start(Window5Avg(AtomToAtomModule)) with fscore 0.9177
Training child program: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(MinResNoseKeypointDistanceSelect())))
DEBUG: f-score 1.04
POP Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(MinResNoseKeypointDistanceSelect()))) with fscore 1.0400
Frontier length is: 8
Total time elapsed is 48.870
CURRENT program has depth 4, fscore 0.4535: Start(Or(Window5Avg(AtomToAtomModule), Window5Avg(OverlapBboxesSelect())))
Training child program: Start(Or(Window5Avg(ResAngleHeadBodySelect()), Window5Avg(OverlapBboxesSelect())))
DEBUG: f-score 0.4425974025974026
New BEST program found:
Start(Or(Window5Avg(ResAngleHeadBodySelect()), Window5Avg(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.4026 | path_cost 0.4426 | time 58.8371
Training child program: Start(Or(Window5Avg(SpeedSelect()), Window5Avg(OverlapBboxesSelect())))
DEBUG: f-score 0.434927536231884
New BEST program found:
Start(Or(Window5Avg(SpeedSelect()), Window5Avg(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3949 | path_cost 0.4349 | time 68.6588
Training child program: Start(Or(Window5Avg(TangentialVelocitySelect()), Window5Avg(OverlapBboxesSelect())))
DEBUG: f-score 0.7235599505562423
Training child program: Start(Or(Window5Avg(AccelerationSelect()), Window5Avg(OverlapBboxesSelect())))
DEBUG: f-score 0.4514490161001789
Training child program: Start(Or(Window5Avg(RelativeSocialAngleSelect()), Window5Avg(OverlapBboxesSelect())))
DEBUG: f-score 0.5455432372505544
Training child program: Start(Or(Window5Avg(AxisRatioSelect()), Window5Avg(OverlapBboxesSelect())))
DEBUG: f-score 0.38587080948487323
New BEST program found:
Start(Or(Window5Avg(AxisRatioSelect()), Window5Avg(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3459 | path_cost 0.3859 | time 109.9964
Training child program: Start(Or(Window5Avg(OverlapBboxesSelect()), Window5Avg(OverlapBboxesSelect())))
DEBUG: f-score 0.3506444605358436
New BEST program found:
Start(Or(Window5Avg(OverlapBboxesSelect()), Window5Avg(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3106 | path_cost 0.3506 | time 119.8187
Training child program: Start(Or(Window5Avg(MinResNoseKeypointDistanceSelect()), Window5Avg(OverlapBboxesSelect())))
DEBUG: f-score 0.36586206896551726
Frontier length is: 0
Total time elapsed is 129.612
BEST programs found:
Start(Or(Window5Avg(ResAngleHeadBodySelect()), Window5Avg(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.4026 | path_cost 0.4426 | time 58.8371
Start(Or(Window5Avg(SpeedSelect()), Window5Avg(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3949 | path_cost 0.4349 | time 68.6588
Start(Or(Window5Avg(AxisRatioSelect()), Window5Avg(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3459 | path_cost 0.3859 | time 109.9964
Start(Or(Window5Avg(OverlapBboxesSelect()), Window5Avg(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3106 | path_cost 0.3506 | time 119.8187
Evaluating program Start(Or(Window5Avg(OverlapBboxesSelect()), Window5Avg(OverlapBboxesSelect()))) on TEST SET
F1 score achieved is 0.5724
Additional performance parameters: {'hamming_accuracy': 0.6996666666666667, 'all_f1s': array([0.76855895, 0.57237779])}
ALGORITHM END
NEAR with Morlet DSL#
How does the programs found by NEAR using the Morlet filter differ from enumeration through the search process? How does the program performance differ from the default DSL?
!yes| python train.py \
--algorithm astar-near \
--exp_name investigation_morlet \
--trial 1 \
--seed 1 \
--dsl_str "morlet" \
--train_data "data/calms21_task1/train_data.npy" \
--test_data "data/calms21_task1/test_data.npy" \
--valid_data "data/calms21_task1/val_data.npy" \
--train_labels "data/calms21_task1/train_investigation_labels.npy" \
--test_labels "data/calms21_task1/test_investigation_labels.npy" \
--valid_labels "data/calms21_task1/val_investigation_labels.npy" \
--input_type "list" \
--output_type "atom" \
--input_size 18 \
--output_size 1 \
--num_labels 1 \
--lossfxn "bcelogits" \
--frontier_capacity 8 \
--max_num_children 10 \
--max_depth 5 \
--max_num_units 32 \
--min_num_units 16 \
--learning_rate 0.0001 \
--neural_epochs 4 \
--symbolic_epochs 12 \
--class_weights "2.0"
Seed is 1
Experiment log and results saved at: results/investigation_morlet_astar-near_sd_1_001
Training root program ...
/content/drive/MyDrive/neurosymbolic_summer_school_notebooks/code_and_data_4/near.py:222: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:210.)
batch_input = [torch.tensor(traj) for traj in batch]
Initial training complete. F1-Score from program is 0.5791
CURRENT program has depth 0, fscore inf: Start(ListToAtomModule)
Training child program: Start(Or(ListToAtomModule, ListToAtomModule))
DEBUG: f-score 0.3788709677419355
Training child program: Start(And(ListToAtomModule, ListToAtomModule))
DEBUG: f-score 0.562713567839196
Training child program: Start(MorletFilterOp(AtomToAtomModule))
DEBUG: f-score 0.5946560846560847
Frontier length is: 3
Total time elapsed is 9.552
CURRENT program has depth 1, fscore 0.3789: Start(Or(ListToAtomModule, ListToAtomModule))
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), ListToAtomModule))
DEBUG: f-score 0.4783430799220274
Frontier length is: 3
Total time elapsed is 12.460
CURRENT program has depth 2, fscore 0.4783: Start(Or(MorletFilterOp(AtomToAtomModule), ListToAtomModule))
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AtomToAtomModule)))
DEBUG: f-score 0.3923357086302454
Frontier length is: 3
Total time elapsed is 14.865
CURRENT program has depth 3, fscore 0.3923: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AtomToAtomModule)))
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(ResAngleHeadBodySelect())))
DEBUG: f-score 0.505909090909091
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(SpeedSelect())))
DEBUG: f-score 0.6207609475951186
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(TangentialVelocitySelect())))
DEBUG: f-score 0.5302244750181028
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AccelerationSelect())))
DEBUG: f-score 0.6098729582577133
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(RelativeSocialAngleSelect())))
DEBUG: f-score 0.6418306636155606
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AxisRatioSelect())))
DEBUG: f-score 0.8447058823529412
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(OverlapBboxesSelect())))
DEBUG: f-score 0.37452914798206277
POP Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AxisRatioSelect()))) with fscore 0.8447
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(MinResNoseKeypointDistanceSelect())))
DEBUG: f-score 0.7757910906298003
POP Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(MinResNoseKeypointDistanceSelect()))) with fscore 0.7758
Frontier length is: 8
Total time elapsed is 33.586
CURRENT program has depth 4, fscore 0.3745: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(OverlapBboxesSelect())))
Training child program: Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(OverlapBboxesSelect())))
DEBUG: f-score 0.4362558502340092
New BEST program found:
Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3963 | path_cost 0.4363 | time 40.4515
Training child program: Start(Or(MorletFilterOp(SpeedSelect()), MorletFilterOp(OverlapBboxesSelect())))
DEBUG: f-score 0.42735818476499193
New BEST program found:
Start(Or(MorletFilterOp(SpeedSelect()), MorletFilterOp(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3874 | path_cost 0.4274 | time 47.4724
Training child program: Start(Or(MorletFilterOp(TangentialVelocitySelect()), MorletFilterOp(OverlapBboxesSelect())))
DEBUG: f-score 0.567647610121837
Training child program: Start(Or(MorletFilterOp(AccelerationSelect()), MorletFilterOp(OverlapBboxesSelect())))
DEBUG: f-score 0.4065594855305467
New BEST program found:
Start(Or(MorletFilterOp(AccelerationSelect()), MorletFilterOp(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3666 | path_cost 0.4066 | time 61.1156
Training child program: Start(Or(MorletFilterOp(RelativeSocialAngleSelect()), MorletFilterOp(OverlapBboxesSelect())))
DEBUG: f-score 0.4129729729729729
Training child program: Start(Or(MorletFilterOp(AxisRatioSelect()), MorletFilterOp(OverlapBboxesSelect())))
DEBUG: f-score 0.4126937269372693
Training child program: Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(OverlapBboxesSelect())))
DEBUG: f-score 0.32441754916792737
New BEST program found:
Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.2844 | path_cost 0.3244 | time 81.5156
Training child program: Start(Or(MorletFilterOp(MinResNoseKeypointDistanceSelect()), MorletFilterOp(OverlapBboxesSelect())))
DEBUG: f-score 0.29561187545257056
New BEST program found:
Start(Or(MorletFilterOp(MinResNoseKeypointDistanceSelect()), MorletFilterOp(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.2556 | path_cost 0.2956 | time 88.2828
Frontier length is: 0
Total time elapsed is 88.287
BEST programs found:
Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3963 | path_cost 0.4363 | time 40.4515
Start(Or(MorletFilterOp(SpeedSelect()), MorletFilterOp(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3874 | path_cost 0.4274 | time 47.4724
Start(Or(MorletFilterOp(AccelerationSelect()), MorletFilterOp(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.3666 | path_cost 0.4066 | time 61.1156
Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.2844 | path_cost 0.3244 | time 81.5156
Start(Or(MorletFilterOp(MinResNoseKeypointDistanceSelect()), MorletFilterOp(OverlapBboxesSelect())))
struct_cost 0.0400 | score 0.2556 | path_cost 0.2956 | time 88.2828
Evaluating program Start(Or(MorletFilterOp(MinResNoseKeypointDistanceSelect()), MorletFilterOp(OverlapBboxesSelect()))) on TEST SET
F1 score achieved is 0.6564
Additional performance parameters: {'hamming_accuracy': 0.7556666666666667, 'all_f1s': array([0.81044738, 0.65635256])}
ALGORITHM END
Visualizing Runtime vs. Accuracy#
To evaluate your NEAR runs, we can take the saved log files in code_and_data/results and plot the total runtime against accuracy.
Optional Exercise: Some hyperparameters that affect runtime and accuracy are listed below. Try changing a few of these and save a performance plot of your results.
neural_epochs: number of epochs to train the neural network approximatormin_num_unitsandmax_num_units: minimum and maximum number of units in the neural network. The network is smaller as the search gets deeper.max_num_children: max number of children for a nodefrontier_capacity: capacity of frontier maintained by the search algorithm
How does the runtime and performance of NEAR compare to enumeration?
# Plotting utility functions
def parse_runtime_f1_from_logs(log_files):
runtime = []
f1 = []
runtime_key = 'Total time elapsed is'
f1_key = 'F1 score achieved is'
for item in log_files:
# If there's a list of list of files corresponding to different random seeds,
# we take the average
if len(item[0]) > 1:
seed_runtime = []
seed_f1 = []
for seed in item:
with open(os.path.join('results', seed, 'log.txt')) as f:
lines = f.readlines()
curr_runtimes = []
for line in lines:
if runtime_key in line:
if line.split(runtime_key)[-1].startswith(':'):
curr_runtimes.append(float(line.split(runtime_key)[-1].strip()[1:]))
else:
curr_runtimes.append(float(line.split(runtime_key)[-1].strip()))
if f1_key in line:
seed_f1.append(float(line.split(f1_key)[-1].strip()))
seed_runtime.append(curr_runtimes[-1])
runtime.append(np.mean(seed_runtime))
f1.append(np.mean(seed_f1))
else:
# There's only 1 seed per run
with open(os.path.join('results', item, 'log.txt')) as f:
lines = f.readlines()
curr_runtimes = []
for line in lines:
if runtime_key in line:
if line.split(runtime_key)[-1].startswith(':'):
curr_runtimes.append(float(line.split(runtime_key)[-1].strip()[1:]))
else:
curr_runtimes.append(float(line.split(runtime_key)[-1].strip()))
if f1_key in line:
f1.append(float(line.split(f1_key)[-1].strip()))
runtime.append(curr_runtimes[-1])
return runtime, f1
def plot_runtime_f1(runtime, f1, labels):
assert(len(runtime) == len(f1) == len(labels))
fig = plt.figure()
for i, item in enumerate(labels):
if len(item[0]) > 1:
item = item[0]
plt.scatter(runtime[i], f1[i], label = item.split('_sd')[0])
plt.xlim([10, 400])
plt.ylim([0.3, 0.75])
plt.xlabel("Runtime (s)")
plt.ylabel("F1 score")
plt.legend(loc='upper center', bbox_to_anchor=(0.5, 1 + 0.1*len(labels)))
# Directory names to plot inside near_code/results
run_names_to_plot = ['investigation_base_enumeration_sd_1_001',
'investigation_morlet_enumeration_sd_1_001',
'investigation_base_astar-near_sd_1_001',
'investigation_morlet_astar-near_sd_1_001']
runtime, f1 = parse_runtime_f1_from_logs(run_names_to_plot)
plot_runtime_f1(runtime, f1, run_names_to_plot)
investigation_base_enumeration_sd_1_001
investigation_morlet_enumeration_sd_1_001
investigation_base_astar-near_sd_1_001
investigation_morlet_astar-near_sd_1_001
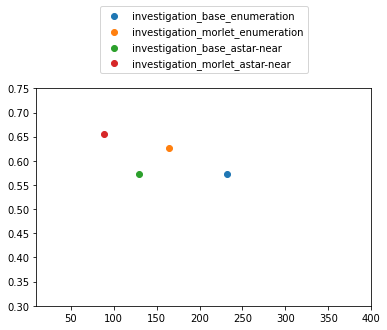
[Optional] Open-Ended Exploration#
Can you improve the performance of neurally-guided program search? Submit your runs on seed 1 (default) to https://forms.gle/peEi6vryaJQejTcn9. Feel free to make any changes to the code! Below are some suggestions:
Modifying neural heuristic: looking at the neural modules in
dsl.ipynb, such asListToAtomModuleorAtomToAtomModuleand the hyperparameters for training the neural approximators, are you able to improve the neural heuristic we currently use? The ideal neural heuristic would be able to be trained quickly, while approximating the program performance closely and is admissible.Modify search space: are there any modifications you can make to the search space, for example, through modifying the DSL or min/max program depth that leads to better runtime and performance?
[Optional] Modify Architecture of AtomToAtom Heuristic#
In dsl.ipynb, the architecture of the neural heuristics used are defined in the Section called Neural Functions. In this section, the AtomToAtomModule in dsl.ipynb uses a 2-layer network in FeedForwardModule as the neural approximator. Modify the network architecture to add a third layer and run NEAR below. Do you observe any changes in performance? Why or why not?
Important: after modifying dsl.ipynb, you will need to re-convert your new dsl to python files, included in the cell below.
!jupyter nbconvert --to python dsl.ipynb
!jupyter nbconvert --to python near.ipynb
!yes| python train.py \
--algorithm astar-near \
--exp_name investigation_morlet_3layer \
--trial 1 \
--seed 1 \
--dsl_str "morlet" \
--train_data "data/calms21_task1/train_data.npy" \
--test_data "data/calms21_task1/test_data.npy" \
--valid_data "data/calms21_task1/val_data.npy" \
--train_labels "data/calms21_task1/train_investigation_labels.npy" \
--test_labels "data/calms21_task1/test_investigation_labels.npy" \
--valid_labels "data/calms21_task1/val_investigation_labels.npy" \
--input_type "list" \
--output_type "atom" \
--input_size 18 \
--output_size 1 \
--num_labels 1 \
--lossfxn "bcelogits" \
--frontier_capacity 8 \
--max_num_children 10 \
--max_depth 5 \
--max_num_units 16 \
--min_num_units 8 \
--learning_rate 0.0001 \
--neural_epochs 4 \
--symbolic_epochs 12 \
--class_weights "2.0"
Result program found in save path, overwrite log and program? [y/n]Seed is 1
Experiment log and results saved at: results/investigation_morlet_3layer_astar-near_sd_1_001
Training root program ...
/content/drive/MyDrive/neurosymbolic_summer_school_notebooks/code_sketch/near_code/near.py:219: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:210.)
batch_input = [torch.tensor(traj) for traj in batch]
Initial training complete. F1-Score from program is 0.1141
CURRENT program has depth 0, fscore inf: Start(ListToAtomModule)
Training child program: Start(Or(ListToAtomModule, ListToAtomModule))
DEBUG: f-score 0.7521428571428572
Training child program: Start(And(ListToAtomModule, ListToAtomModule))
DEBUG: f-score 0.9096103896103896
Training child program: Start(MorletFilterOp(AtomToAtomModule))
DEBUG: f-score 0.8221019108280255
Frontier length is: 3
Total time elapsed is 8.946
CURRENT program has depth 1, fscore 0.7521: Start(Or(ListToAtomModule, ListToAtomModule))
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), ListToAtomModule))
DEBUG: f-score 0.8214691943127963
Frontier length is: 3
Total time elapsed is 12.036
CURRENT program has depth 2, fscore 0.8215: Start(Or(MorletFilterOp(AtomToAtomModule), ListToAtomModule))
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AtomToAtomModule)))
DEBUG: f-score 0.6426143790849674
Frontier length is: 3
Total time elapsed is 14.759
CURRENT program has depth 3, fscore 0.6426: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AtomToAtomModule)))
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(ResAngleHeadBodySelect())))
DEBUG: f-score 0.6952667578659371
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(SpeedSelect())))
DEBUG: f-score 0.891400730816078
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(TangentialVelocitySelect())))
DEBUG: f-score 0.9013396004700353
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AccelerationSelect())))
DEBUG: f-score 0.5935390199637023
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(RelativeSocialAngleSelect())))
DEBUG: f-score 0.6602046035805627
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AxisRatioSelect())))
DEBUG: f-score 0.7183216783216784
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(OverlapBboxesSelect())))
DEBUG: f-score 0.9151814223512337
POP Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(OverlapBboxesSelect()))) with fscore 0.9152
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(MinResNoseKeypointDistanceSelect())))
DEBUG: f-score 1.0381834695731154
POP Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(MinResNoseKeypointDistanceSelect()))) with fscore 1.0382
Frontier length is: 8
Total time elapsed is 34.777
CURRENT program has depth 4, fscore 0.5935: Start(Or(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AccelerationSelect())))
Training child program: Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(AccelerationSelect())))
DEBUG: f-score 0.6286402753872634
New BEST program found:
Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(AccelerationSelect())))
struct_cost 0.0400 | score 0.5886 | path_cost 0.6286 | time 41.8963
Training child program: Start(Or(MorletFilterOp(SpeedSelect()), MorletFilterOp(AccelerationSelect())))
DEBUG: f-score 0.646951871657754
Training child program: Start(Or(MorletFilterOp(TangentialVelocitySelect()), MorletFilterOp(AccelerationSelect())))
DEBUG: f-score 0.6453811659192825
Training child program: Start(Or(MorletFilterOp(AccelerationSelect()), MorletFilterOp(AccelerationSelect())))
DEBUG: f-score 0.6999378881987578
Training child program: Start(Or(MorletFilterOp(RelativeSocialAngleSelect()), MorletFilterOp(AccelerationSelect())))
DEBUG: f-score 0.6929230769230769
Training child program: Start(Or(MorletFilterOp(AxisRatioSelect()), MorletFilterOp(AccelerationSelect())))
DEBUG: f-score 0.7631352718078381
Training child program: Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(AccelerationSelect())))
DEBUG: f-score 0.3221292775665399
New BEST program found:
Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(AccelerationSelect())))
struct_cost 0.0400 | score 0.2821 | path_cost 0.3221 | time 83.3394
Training child program: Start(Or(MorletFilterOp(MinResNoseKeypointDistanceSelect()), MorletFilterOp(AccelerationSelect())))
DEBUG: f-score 1.0346127946127945
Frontier length is: 0
Total time elapsed is 90.187
BEST programs found:
Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(AccelerationSelect())))
struct_cost 0.0400 | score 0.5886 | path_cost 0.6286 | time 41.8963
Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(AccelerationSelect())))
struct_cost 0.0400 | score 0.2821 | path_cost 0.3221 | time 83.3394
Evaluating program Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(AccelerationSelect()))) on TEST SET
F1 score achieved is 0.6300
Additional performance parameters: {'hamming_accuracy': 0.749, 'all_f1s': array([0.81008827, 0.62997543])}
ALGORITHM END
[Optional] NEAR: IDDFS Search - Morlet DSL#
The admissible heuristics used by NEAR is compatible with different search strategies - here, we use iterative deepening depth-first search (IDDFS) instead of A* search through the program space. IDDFS is a search strategy where depth-limited version of depth-first search is run repreatedly with increasing depth limits.
How does the performance of IDDFS compare to A* on this dataset?
!yes| python train.py \
--algorithm iddfs-near \
--exp_name investigation_morlet \
--trial 1 \
--seed 1 \
--dsl_str "morlet" \
--train_data "data/calms21_task1/train_data.npy" \
--test_data "data/calms21_task1/test_data.npy" \
--valid_data "data/calms21_task1/val_data.npy" \
--train_labels "data/calms21_task1/train_investigation_labels.npy" \
--test_labels "data/calms21_task1/test_investigation_labels.npy" \
--valid_labels "data/calms21_task1/val_investigation_labels.npy" \
--input_type "list" \
--output_type "atom" \
--input_size 18 \
--output_size 1 \
--num_labels 1 \
--lossfxn "bcelogits" \
--frontier_capacity 5 \
--max_num_children 10 \
--max_depth 5 \
--max_num_units 16 \
--min_num_units 8 \
--learning_rate 0.0001 \
--neural_epochs 4 \
--symbolic_epochs 12 \
--class_weights "2.0"
Result program found in save path, overwrite log and program? [y/n]Seed is 1
Experiment log and results saved at: results/investigation_morlet_iddfs-near_sd_1_001
Training root program ...
/content/drive/MyDrive/neurosymbolic_summer_school_notebooks/code_sketch/near_code/near.py:219: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:210.)
batch_input = [torch.tensor(traj) for traj in batch]
Initial training complete. Score from program is 0.1141
CURRENT program has depth 0, fscore inf: Start(ListToAtomModule)
Frontier length is: 0
Frontier length is now 0
Empty frontier, moving to next depth level
DEBUG: time since start is 8.520
Starting iterative deepening with depth 2
CURRENT program has depth 1, fscore 0.4796: Start(MorletFilterOp(AtomToAtomModule))
New BEST program found:
Start(MorletFilterOp(ResAngleHeadBodySelect()))
struct_cost 0.0100 | score 0.5811 | path_cost 0.5911 | time 16.6010
New BEST program found:
Start(MorletFilterOp(SpeedSelect()))
struct_cost 0.0100 | score 0.5544 | path_cost 0.5644 | time 22.2089
New BEST program found:
Start(MorletFilterOp(MinResNoseKeypointDistanceSelect()))
struct_cost 0.0100 | score 0.2428 | path_cost 0.2528 | time 55.2963
Frontier length is: 2
PRUNE from frontier: Start(And(ListToAtomModule, ListToAtomModule)) with f_score 0.9547079037800688
PRUNE from frontier: Start(Or(ListToAtomModule, ListToAtomModule)) with f_score 0.7317903930131004
Frontier length is now 0
Empty frontier, moving to next depth level
DEBUG: time since start is 55.300
Starting iterative deepening with depth 3
CURRENT program has depth 2, fscore 0.5148: Start(MorletFilterOp(SimpleITE(AtomToAtomModule, AtomToAtomModule, AtomToAtomModule)))
POP Start(MorletFilterOp(SimpleITE(TangentialVelocitySelect(), AtomToAtomModule, AtomToAtomModule))) with fscore 0.6473
POP Start(MorletFilterOp(SimpleITE(AccelerationSelect(), AtomToAtomModule, AtomToAtomModule))) with fscore 0.7745
POP Start(MorletFilterOp(SimpleITE(SpeedSelect(), AtomToAtomModule, AtomToAtomModule))) with fscore 0.9958
Frontier length is: 0
Frontier length is now 0
Empty frontier, moving to next depth level
DEBUG: time since start is 74.843
Starting iterative deepening with depth 4
CURRENT program has depth 3, fscore 0.4410: Start(MorletFilterOp(SimpleITE(MinResNoseKeypointDistanceSelect(), AtomToAtomModule, AtomToAtomModule)))
POP Start(MorletFilterOp(SimpleITE(MinResNoseKeypointDistanceSelect(), AccelerationSelect(), AtomToAtomModule))) with fscore 0.6534
POP Start(MorletFilterOp(SimpleITE(MinResNoseKeypointDistanceSelect(), SpeedSelect(), AtomToAtomModule))) with fscore 0.7858
POP Start(MorletFilterOp(SimpleITE(MinResNoseKeypointDistanceSelect(), OverlapBboxesSelect(), AtomToAtomModule))) with fscore 0.9602
Frontier length is: 4
PRUNE from frontier: Start(MorletFilterOp(SimpleITE(OverlapBboxesSelect(), AtomToAtomModule, AtomToAtomModule))) with f_score 0.6256031128404669
PRUNE from frontier: Start(MorletFilterOp(SimpleITE(AxisRatioSelect(), AtomToAtomModule, AtomToAtomModule))) with f_score 0.45772151898734176
PRUNE from frontier: Start(MorletFilterOp(SimpleITE(RelativeSocialAngleSelect(), AtomToAtomModule, AtomToAtomModule))) with f_score 0.48800000000000004
PRUNE from frontier: Start(MorletFilterOp(SimpleITE(ResAngleHeadBodySelect(), AtomToAtomModule, AtomToAtomModule))) with f_score 0.5257142857142858
Frontier length is now 0
Empty frontier, moving to next depth level
DEBUG: time since start is 94.350
Starting iterative deepening with depth 5
CURRENT program has depth 4, fscore 0.3113: Start(MorletFilterOp(SimpleITE(MinResNoseKeypointDistanceSelect(), MinResNoseKeypointDistanceSelect(), AtomToAtomModule)))
Frontier length is: 4
PRUNE from frontier: Start(MorletFilterOp(SimpleITE(MinResNoseKeypointDistanceSelect(), AxisRatioSelect(), AtomToAtomModule))) with f_score 0.644306864064603
PRUNE from frontier: Start(MorletFilterOp(SimpleITE(MinResNoseKeypointDistanceSelect(), RelativeSocialAngleSelect(), AtomToAtomModule))) with f_score 0.5185478547854786
PRUNE from frontier: Start(MorletFilterOp(SimpleITE(MinResNoseKeypointDistanceSelect(), TangentialVelocitySelect(), AtomToAtomModule))) with f_score 0.4167441860465117
PRUNE from frontier: Start(MorletFilterOp(SimpleITE(MinResNoseKeypointDistanceSelect(), ResAngleHeadBodySelect(), AtomToAtomModule))) with f_score 0.5876190476190477
Frontier length is now 0
Empty frontier, moving to next depth level
DEBUG: time since start is 149.124
Max depth 5 reached. Exiting.
BEST programs found:
Start(MorletFilterOp(ResAngleHeadBodySelect()))
struct_cost 0.0100 | score 0.5811 | path_cost 0.5911 | time 16.6010
Start(MorletFilterOp(SpeedSelect()))
struct_cost 0.0100 | score 0.5544 | path_cost 0.5644 | time 22.2089
Start(MorletFilterOp(MinResNoseKeypointDistanceSelect()))
struct_cost 0.0100 | score 0.2428 | path_cost 0.2528 | time 55.2963
Evaluating program Start(MorletFilterOp(MinResNoseKeypointDistanceSelect())) on TEST SET
F1 score achieved is 0.6564
Additional performance parameters: {'hamming_accuracy': 0.7773333333333333, 'all_f1s': array([0.83530572, 0.6563786 ])}
ALGORITHM END
[Optional] Additional Experiments: Test on Other Behavior Classes#
In behavior analysis, animals exhibit a wide range of behaviors, and the goal of behavioral neuroscience is to learn the neural basis of these behaviors. Investigation vs. no investigation is one example of a human-defined behavior, but there’s also behaviors such as mount, attack, rearing, approach, groom, …
Here, we provide an additional set of behavior annotations for mount. How does the DSL and algorithm you developed compare to using enumeration as a baseline for program search? Mount is a relatively rare class compared to investigation - how do the performances compare?
!yes | python train.py \
--algorithm enumeration \
--exp_name investigation_morlet \
--trial 1 \
--seed 1 \
--dsl_str "morlet" \
--train_data "data/calms21_task1/train_data.npy" \
--test_data "data/calms21_task1/test_data.npy" \
--valid_data "data/calms21_task1/val_data.npy" \
--train_labels "data/calms21_task1/train_mount_labels.npy" \
--test_labels "data/calms21_task1/test_mount_labels.npy" \
--valid_labels "data/calms21_task1/val_mount_labels.npy" \
--input_type "list" \
--output_type "atom" \
--input_size 18 \
--output_size 1 \
--num_labels 1 \
--lossfxn "bcelogits" \
--learning_rate 0.0001 \
--symbolic_epochs 12 \
--max_num_programs 25 \
--class_weights "2.0"
Result program found in save path, overwrite log and program? [y/n]Seed is 1
Experiment log and results saved at: results/investigation_morlet_enumeration_sd_1_001
DEBUG: starting enumerative synthesis with depth 1
DEBUG: 0 programs found
DEBUG: starting enumerative synthesis with depth 2
DEBUG: 8 programs found
DEBUG: starting enumerative synthesis with depth 3
DEBUG: 8 programs found
DEBUG: starting enumerative synthesis with depth 4
DEBUG: 8 programs found
DEBUG: starting enumerative synthesis with depth 5
DEBUG: 648 programs found
Symbolic Synthesis: generated 648/25 symbolic programs from candidate program.
Training candidate program (1/25) Start(MorletFilterOp(ResAngleHeadBodySelect()))
/content/drive/MyDrive/neurosymbolic_summer_school_notebooks/code_sketch/near_code/near.py:219: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:210.)
batch_input = [torch.tensor(traj) for traj in batch]
Structural cost is 0.01 with structural penalty 0.01
Time to train child 5.567
Total time elapsed is: 5.567
New tentative BEST program found:
Start(MorletFilterOp(ResAngleHeadBodySelect()))
struct_cost 0.0100 | score 1.0000 | path_cost 1.0100 | time 5.5675
Training candidate program (2/25) Start(MorletFilterOp(SpeedSelect()))
Structural cost is 0.01 with structural penalty 0.01
Time to train child 5.633
Total time elapsed is: 11.204
New tentative BEST program found:
Start(MorletFilterOp(SpeedSelect()))
struct_cost 0.0100 | score 0.9581 | path_cost 0.9681 | time 11.2037
Training candidate program (3/25) Start(MorletFilterOp(TangentialVelocitySelect()))
Structural cost is 0.01 with structural penalty 0.01
Time to train child 5.570
Total time elapsed is: 16.776
New tentative BEST program found:
Start(MorletFilterOp(TangentialVelocitySelect()))
struct_cost 0.0100 | score 0.9576 | path_cost 0.9676 | time 16.7764
Training candidate program (4/25) Start(MorletFilterOp(AccelerationSelect()))
Structural cost is 0.01 with structural penalty 0.01
Time to train child 5.575
Total time elapsed is: 22.354
New tentative BEST program found:
Start(MorletFilterOp(AccelerationSelect()))
struct_cost 0.0100 | score 0.8676 | path_cost 0.8776 | time 22.3540
Training candidate program (5/25) Start(MorletFilterOp(RelativeSocialAngleSelect()))
Structural cost is 0.01 with structural penalty 0.01
Time to train child 5.480
Total time elapsed is: 27.837
Training candidate program (6/25) Start(MorletFilterOp(AxisRatioSelect()))
Structural cost is 0.01 with structural penalty 0.01
Time to train child 5.506
Total time elapsed is: 33.343
Training candidate program (7/25) Start(MorletFilterOp(OverlapBboxesSelect()))
Structural cost is 0.01 with structural penalty 0.01
Time to train child 5.543
Total time elapsed is: 38.886
Training candidate program (8/25) Start(MorletFilterOp(MinResNoseKeypointDistanceSelect()))
Structural cost is 0.01 with structural penalty 0.01
Time to train child 5.603
Total time elapsed is: 44.489
Training candidate program (9/25) Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(ResAngleHeadBodySelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.907
Total time elapsed is: 51.397
Training candidate program (10/25) Start(Or(MorletFilterOp(SpeedSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.869
Total time elapsed is: 58.266
Training candidate program (11/25) Start(Or(MorletFilterOp(TangentialVelocitySelect()), MorletFilterOp(ResAngleHeadBodySelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.883
Total time elapsed is: 65.149
Training candidate program (12/25) Start(Or(MorletFilterOp(AccelerationSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.994
Total time elapsed is: 72.144
Training candidate program (13/25) Start(Or(MorletFilterOp(RelativeSocialAngleSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.777
Total time elapsed is: 78.921
Training candidate program (14/25) Start(Or(MorletFilterOp(AxisRatioSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.769
Total time elapsed is: 85.690
Training candidate program (15/25) Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.775
Total time elapsed is: 92.466
Training candidate program (16/25) Start(Or(MorletFilterOp(MinResNoseKeypointDistanceSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.724
Total time elapsed is: 99.190
Training candidate program (17/25) Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(SpeedSelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.900
Total time elapsed is: 106.090
Training candidate program (18/25) Start(Or(MorletFilterOp(SpeedSelect()), MorletFilterOp(SpeedSelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.935
Total time elapsed is: 113.025
Training candidate program (19/25) Start(Or(MorletFilterOp(TangentialVelocitySelect()), MorletFilterOp(SpeedSelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.794
Total time elapsed is: 119.819
Training candidate program (20/25) Start(Or(MorletFilterOp(AccelerationSelect()), MorletFilterOp(SpeedSelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.810
Total time elapsed is: 126.630
Training candidate program (21/25) Start(Or(MorletFilterOp(RelativeSocialAngleSelect()), MorletFilterOp(SpeedSelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.820
Total time elapsed is: 133.450
Training candidate program (22/25) Start(Or(MorletFilterOp(AxisRatioSelect()), MorletFilterOp(SpeedSelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.813
Total time elapsed is: 140.263
Training candidate program (23/25) Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(SpeedSelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.767
Total time elapsed is: 147.030
Training candidate program (24/25) Start(Or(MorletFilterOp(MinResNoseKeypointDistanceSelect()), MorletFilterOp(SpeedSelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.796
Total time elapsed is: 153.826
Training candidate program (25/25) Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(TangentialVelocitySelect())))
Structural cost is 0.04 with structural penalty 0.01
Time to train child 6.770
Total time elapsed is: 160.597
Total time elapsed is 160.639
BEST programs found:
Start(Or(MorletFilterOp(MinResNoseKeypointDistanceSelect()), MorletFilterOp(SpeedSelect())))
struct_cost 0.0400 | score 0.9965 | path_cost 1.0365 | time 153.8263
Start(Or(MorletFilterOp(MinResNoseKeypointDistanceSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
struct_cost 0.0400 | score 0.9964 | path_cost 1.0364 | time 99.1899
Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(TangentialVelocitySelect())))
struct_cost 0.0400 | score 0.9861 | path_cost 1.0261 | time 160.5970
Start(Or(MorletFilterOp(AxisRatioSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
struct_cost 0.0400 | score 0.9815 | path_cost 1.0215 | time 85.6902
Start(MorletFilterOp(ResAngleHeadBodySelect()))
struct_cost 0.0100 | score 1.0000 | path_cost 1.0100 | time 5.5675
Start(Or(MorletFilterOp(AxisRatioSelect()), MorletFilterOp(SpeedSelect())))
struct_cost 0.0400 | score 0.9673 | path_cost 1.0073 | time 140.2630
Start(MorletFilterOp(OverlapBboxesSelect()))
struct_cost 0.0100 | score 0.9971 | path_cost 1.0071 | time 38.8865
Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(ResAngleHeadBodySelect())))
struct_cost 0.0400 | score 0.9665 | path_cost 1.0065 | time 51.3970
Start(Or(MorletFilterOp(AccelerationSelect()), MorletFilterOp(SpeedSelect())))
struct_cost 0.0400 | score 0.9658 | path_cost 1.0058 | time 126.6298
Start(Or(MorletFilterOp(TangentialVelocitySelect()), MorletFilterOp(ResAngleHeadBodySelect())))
struct_cost 0.0400 | score 0.9608 | path_cost 1.0008 | time 65.1496
Start(Or(MorletFilterOp(ResAngleHeadBodySelect()), MorletFilterOp(SpeedSelect())))
struct_cost 0.0400 | score 0.9566 | path_cost 0.9966 | time 106.0904
Start(Or(MorletFilterOp(RelativeSocialAngleSelect()), MorletFilterOp(SpeedSelect())))
struct_cost 0.0400 | score 0.9561 | path_cost 0.9961 | time 133.4501
Start(Or(MorletFilterOp(AccelerationSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
struct_cost 0.0400 | score 0.9520 | path_cost 0.9920 | time 72.1440
Start(Or(MorletFilterOp(TangentialVelocitySelect()), MorletFilterOp(SpeedSelect())))
struct_cost 0.0400 | score 0.9379 | path_cost 0.9779 | time 119.8194
Start(Or(MorletFilterOp(RelativeSocialAngleSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
struct_cost 0.0400 | score 0.9332 | path_cost 0.9732 | time 78.9208
Start(Or(MorletFilterOp(SpeedSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
struct_cost 0.0400 | score 0.9320 | path_cost 0.9720 | time 58.2664
Start(Or(MorletFilterOp(SpeedSelect()), MorletFilterOp(SpeedSelect())))
struct_cost 0.0400 | score 0.9315 | path_cost 0.9715 | time 113.0255
Start(MorletFilterOp(SpeedSelect()))
struct_cost 0.0100 | score 0.9581 | path_cost 0.9681 | time 11.2037
Start(MorletFilterOp(TangentialVelocitySelect()))
struct_cost 0.0100 | score 0.9576 | path_cost 0.9676 | time 16.7764
Start(MorletFilterOp(RelativeSocialAngleSelect()))
struct_cost 0.0100 | score 0.9454 | path_cost 0.9554 | time 27.8368
Start(MorletFilterOp(MinResNoseKeypointDistanceSelect()))
struct_cost 0.0100 | score 0.9151 | path_cost 0.9251 | time 44.4893
Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(SpeedSelect())))
struct_cost 0.0400 | score 0.8845 | path_cost 0.9245 | time 147.0305
Start(MorletFilterOp(AxisRatioSelect()))
struct_cost 0.0100 | score 0.9096 | path_cost 0.9196 | time 33.3433
Start(Or(MorletFilterOp(OverlapBboxesSelect()), MorletFilterOp(ResAngleHeadBodySelect())))
struct_cost 0.0400 | score 0.8784 | path_cost 0.9184 | time 92.4659
Start(MorletFilterOp(AccelerationSelect()))
struct_cost 0.0100 | score 0.8676 | path_cost 0.8776 | time 22.3540
Evaluating program Start(MorletFilterOp(AccelerationSelect())) on TEST SET
F1 score achieved is 0.1370
Additional performance parameters: {'hamming_accuracy': 0.727, 'all_f1s': array([0.83785389, 0.1369863 ])}
ALGORITHM END
!yes| python train.py \
--algorithm astar-near \
--exp_name investigation_morlet \
--trial 1 \
--seed 1 \
--dsl_str "morlet" \
--train_data "data/calms21_task1/train_data.npy" \
--test_data "data/calms21_task1/test_data.npy" \
--valid_data "data/calms21_task1/val_data.npy" \
--train_labels "data/calms21_task1/train_mount_labels.npy" \
--test_labels "data/calms21_task1/test_mount_labels.npy" \
--valid_labels "data/calms21_task1/val_mount_labels.npy" \
--input_type "list" \
--output_type "atom" \
--input_size 18 \
--output_size 1 \
--num_labels 1 \
--lossfxn "bcelogits" \
--frontier_capacity 8 \
--max_num_children 10 \
--max_depth 5 \
--max_num_units 32 \
--min_num_units 16 \
--learning_rate 0.0001 \
--neural_epochs 4 \
--symbolic_epochs 12 \
--class_weights "2.0"
Result program found in save path, overwrite log and program? [y/n]Seed is 1
Experiment log and results saved at: results/investigation_morlet_astar-near_sd_1_001
Training root program ...
/content/drive/MyDrive/neurosymbolic_summer_school_notebooks/code_sketch/near_code/near.py:219: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:210.)
batch_input = [torch.tensor(traj) for traj in batch]
Initial training complete. F1-Score from program is 0.3256
CURRENT program has depth 0, fscore inf: Start(ListToAtomModule)
Training child program: Start(Or(ListToAtomModule, ListToAtomModule))
DEBUG: f-score 0.6866666666666668
Training child program: Start(And(ListToAtomModule, ListToAtomModule))
DEBUG: f-score 0.6376470588235293
Training child program: Start(MorletFilterOp(AtomToAtomModule))
DEBUG: f-score 0.9772131147540983
Frontier length is: 3
Total time elapsed is 8.758
CURRENT program has depth 1, fscore 0.6376: Start(And(ListToAtomModule, ListToAtomModule))
Training child program: Start(And(MorletFilterOp(AtomToAtomModule), ListToAtomModule))
DEBUG: f-score 0.48882352941176477
Frontier length is: 3
Total time elapsed is 11.837
CURRENT program has depth 2, fscore 0.4888: Start(And(MorletFilterOp(AtomToAtomModule), ListToAtomModule))
Training child program: Start(And(MorletFilterOp(AtomToAtomModule), MorletFilterOp(AtomToAtomModule)))
DEBUG: f-score 1.04
Frontier length is: 3
Total time elapsed is 14.551
CURRENT program has depth 1, fscore 0.6867: Start(Or(ListToAtomModule, ListToAtomModule))
Training child program: Start(Or(MorletFilterOp(AtomToAtomModule), ListToAtomModule))
DEBUG: f-score 0.9972131147540984
Frontier length is: 3
Total time elapsed is 17.611
CURRENT program has depth 1, fscore 0.9772: Start(MorletFilterOp(AtomToAtomModule))
Training child program: Start(MorletFilterOp(SimpleITE(AtomToAtomModule, AtomToAtomModule, AtomToAtomModule)))
DEBUG: f-score 1.04
Training child program: Start(MorletFilterOp(ResAngleHeadBodySelect()))
DEBUG: f-score 0.9843589743589743
New BEST program found:
Start(MorletFilterOp(ResAngleHeadBodySelect()))
struct_cost 0.0100 | score 0.9744 | path_cost 0.9844 | time 25.9099
Training child program: Start(MorletFilterOp(SpeedSelect()))
DEBUG: f-score 0.9462912400455062
New BEST program found:
Start(MorletFilterOp(SpeedSelect()))
struct_cost 0.0100 | score 0.9363 | path_cost 0.9463 | time 31.3697
Training child program: Start(MorletFilterOp(TangentialVelocitySelect()))
DEBUG: f-score 0.9514414414414415
Training child program: Start(MorletFilterOp(AccelerationSelect()))
DEBUG: f-score 0.967962813257882
Training child program: Start(MorletFilterOp(RelativeSocialAngleSelect()))
DEBUG: f-score 0.9563667820069204
Training child program: Start(MorletFilterOp(AxisRatioSelect()))
DEBUG: f-score 0.8934244080145719
New BEST program found:
Start(MorletFilterOp(AxisRatioSelect()))
struct_cost 0.0100 | score 0.8834 | path_cost 0.8934 | time 53.1102
Training child program: Start(MorletFilterOp(OverlapBboxesSelect()))
DEBUG: f-score 1.0085174203113416
Training child program: Start(MorletFilterOp(MinResNoseKeypointDistanceSelect()))
DEBUG: f-score 1.01
Frontier length is: 0
Total time elapsed is 64.072
BEST programs found:
Start(MorletFilterOp(ResAngleHeadBodySelect()))
struct_cost 0.0100 | score 0.9744 | path_cost 0.9844 | time 25.9099
Start(MorletFilterOp(SpeedSelect()))
struct_cost 0.0100 | score 0.9363 | path_cost 0.9463 | time 31.3697
Start(MorletFilterOp(AxisRatioSelect()))
struct_cost 0.0100 | score 0.8834 | path_cost 0.8934 | time 53.1102
Evaluating program Start(MorletFilterOp(AxisRatioSelect())) on TEST SET
F1 score achieved is 0.3304
Additional performance parameters: {'hamming_accuracy': 0.6946666666666667, 'all_f1s': array([0.80224525, 0.33040936])}
ALGORITHM END
Acknowledgements: This notebook was developed by Jennifer J. Sun (Caltech) and Atharva Sengal (UT Austin) for the neurosymbolic summer school. The data subset is processed from CalMS21 and the DSL is developed by by Megan Tjandrasuwita (MIT) from her work on Interpreting Expert Annotation Differences in Animal Behavior. Megan’s work is partly based on NEAR by Ameesh Shah (Berkeley) and Eric Zhan (Argo).